


An Introduction to RedStone Oracles, and their Oracle-On-Demand Model


This article introduces RedStone oracles and their novel model, set to improve the way data is currently delivered to blockchain networks, dApps, and users.
As always, for an introduction to what Oracles are and how they work, please refer to my previous article:
On Greek Mythology and Trustless Oracles

In Ancient Greece, oracles were revered individuals known for their exceptional wisdom and ability to provide insights and prophetic predictions of the future. They were believed to serve as portals through which the gods communicated directly with people.
Whenever assessing a centralized or decentralized architecture for oracles, several tradeoffs must be considered.
While everyone is always arguing for decentralization, pragmatically, this has to come as a slow and iterative shift. Moving to fully decentralized oracles also has its trade-offs, as they are more expensive, slower to react to crises (such as the USDC depeg) and harder to innovate, as it is much tougher to keep on expanding and making a decentralized system more complicated than it already is.

With that in mind, RedStone creates a new Oracle model, which is more flexible in terms of the products offered and the diverse data types supported.
Why do we need RedStone Oracles?
Nowadays, oracles work by creating a smart contract on a blockchain (Ethereum, Arbitrum, etc.) and having a set of nodes that push data in an interval to their smart contracts, updating the data (e.g., price feed of a specific token).
With any update, the gas fees of publishing the data must be covered, which increases in volatile markets when the price deviates faster (thus incurring more gas costs).
The problem with constantly publishing updates in intervals presents itself in case there’s a lack of usage in the protocol.
Let’s have an example where a smart contract updates the price of a token every 15 minutes, but no one interacts with it for 2 hours: as a consequence, all the updates done during this period effectively went to waste.
The current system is, therefore, limited in terms of cost efficiency and flexibility, posing the following problems:
Pushing data at regular intervals without accounting for actual usage increases costs and is a waste of resources.
The monolithic infrastructure required poses limitations in terms of scalability, making it harder, for instance, to list new assets.
Protocols have limited permissions on customization concerning data sources and data update conditions.
Aside from working using this model, Redstone creates a new model: Oracle-on-demand.
Using this model, the data updates hit the Data Distribution Layer (a permissionless off-chain component), where data providers sign data packages available for anyone to pick up as they like — and post them, updating the data feeds.
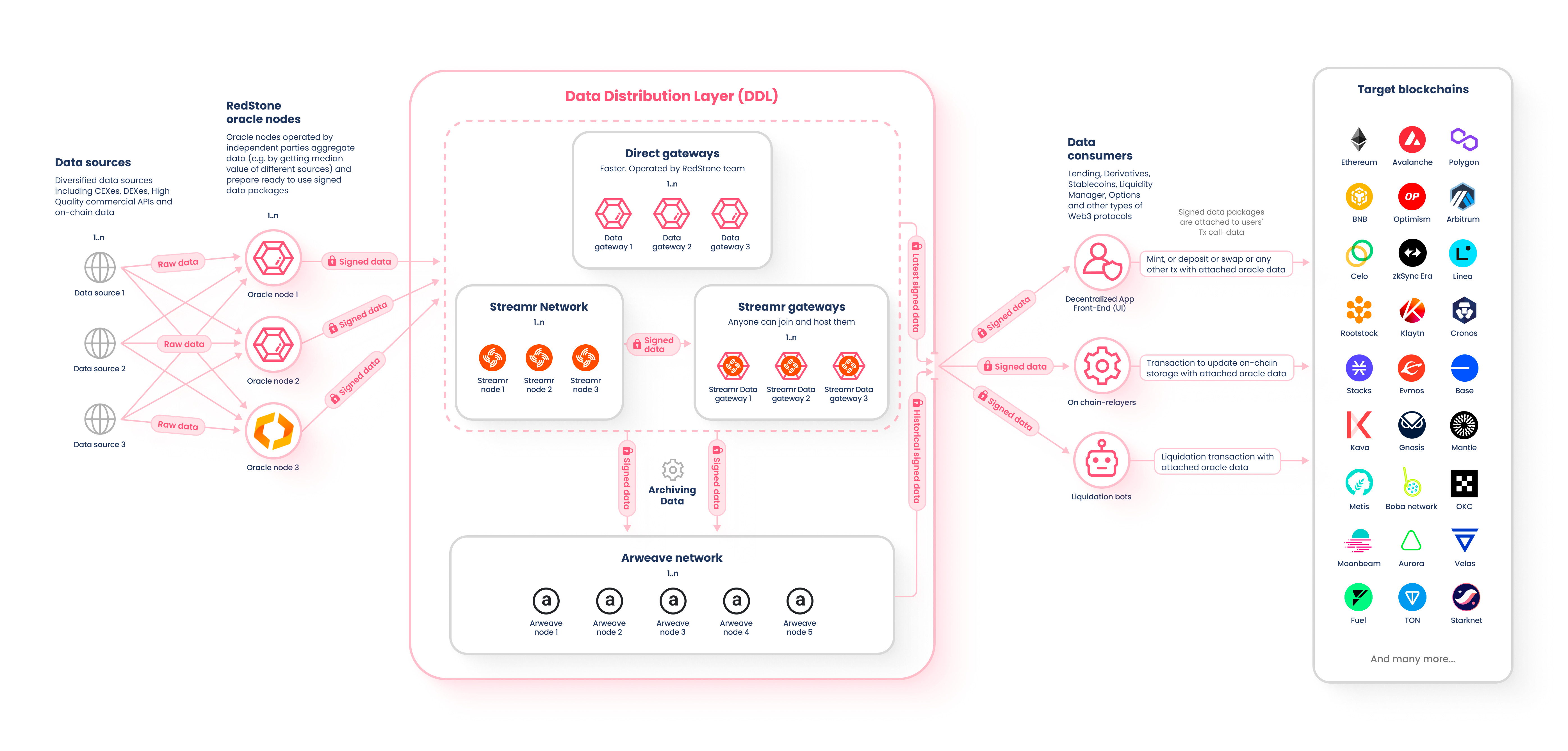
The data gets updated on-demand as users transact on the protocols and not at regular intervals. This way, Oracle-on-demand reduces the waste of updates, only delivering transaction data when needed.
This is particularly interesting given that data feeds are mainly required by dApps and users interacting rather than blockchain networks themselves.

RedStone solution:
No need for continuous data delivery at intervals
Users can pick up and deliver signed Oracle data on-chain.
Aligned tokenomics and incentives for data providers, ensuring the network's correct functioning: every provider is required to publish the scope, the source, and the frequency of updates, and they must also lock a certain number of tokens for a “set period of time”.
Data providers are accountable for their actions
The Oracle-on-demand is a modular design that puts the data first into an off-chain Data Availability Layer and then gets fetched on-chain, allowing for much more granular data provision (e.g. more assets and cheaper data).
One of the unique selling propositions of this model is that it allows RedStone to deliver data that is not available anywhere else.
In fact, RedStone specializes in “yield-bearing collateral for lending markets, especially LSTs & LRTs”.
The fact that the price feeds are chain agnostic means they can be integrated with EVM, non-EVM, Rollups, Rollup-as-a-Service, and even EigenLayer AVS.

Customised Data Consumption Solutions
Redstone features three dedicated models of data consumption, reflecting the need to develop a more tailored delivery of oracle data.
They push forward the concept of modular oracles, contrary to the one-oracle-fits-all model, where data delivery depends on specific use cases (how the data is delivered, whether the frequency or cost is important, and many more variables)
Here’s a summary of the three different solutions provided by RedStone:
RedStone Core (Pull) - on-demand oracle
Data is not pushed at intervals, but only when the user sends a transaction via the dApps and goes on-chain
To that user transaction, Redstone attaches signed data packages that end up being delivered to the destination blockchain and utilized for data updates.
With the lowest gas costs and a few seconds of latency, dApp users deliver signed data packages on demand to the destination chain.
RedStone Classic (Push)
This model is comparable to the traditional Oracles model, with the exception of dApps getting full control over the data source and update conditions.
RedStone X (Zero-latency)
This model is developed in collaboration with GMX and features a front-running protection mechanism for protocols requiring an advanced design, such as Perps & Options protocols.
How is front-running protection enabled?
The user creates an order (e.g. short position)
The order goes to the specific dApp where it has been created
The dApp will send to the blockchain in block n (not executed)
While the order is published on-chain, the price is not visible: at this moment, in fact, the price is only visible in RedStone’s off-chain data distribution layer. Within that layer, anyone can see the price and the order submitted, connect the two, and send them back on the dApp
The transaction gets then executed in block n+1: in this sense, there is a small delay between the order and execution that becomes negligible in high-performing chains.
In this way, as the price is not publicly visible, malicious actors cannot extract value from transactions using RedStone X.
RedStone offers two pricing models:
Monthly fee (+ custom work, updates, support)
A revenue-share model
In both cases, they result in better cost efficiency, as you will only pay for the data you effectively need.
Verifiable cross-chain Randomness is also under development by the team.
More on RedStone:
The price feeds come from multiple sources such as off-chain DEX'ed (Binance, Coinbase & Kraken, etc.), on-chain DEX'es (Uniswap, Sushiswap, Balancer, etc.) and aggregators (CoinmarketCap, Coingecko, Kaiko). Currently, we've got more than 50 sources integrated.
The data is aggregated in independent nodes operated by data providers using various methodologies (eg. median, TWAP, LWAP) and safety measures like outliers detection. The cleaned and processed data is then signed by node operators underwriting the quality.
RedStone does not have a token — YET.
In their own words, they envision the token to “facilitate a data-sharing ecosystem by incentivizing participants to produce, publish, and validate data in a continuous and diligent way”.
The end users who benefit from access to valuable information use tokens to reward providers that published this data. The exact fee and the subscription terms are at the discretion of the provider and depend on their effort, demand for data and potential competition.
What if there’s a disagreement on the quality of the data? In case of disputes, RedStone features a fallback procedure. In the future, this process could eventually be facilitated by tokens, rewarding/punishing the juries.

Podcast on RedStone Oracles:
https://twitter.com/redstone_defi/status/1761074333664063622
On Kelp, Renzo Integration & LRTs:
https://twitter.com/redstone_defi/status/1760998051194573109
https://twitter.com/redstone_defi/status/1760741284111896625
https://twitter.com/redstone_defi/status/1760680941541110084
Wow interesting project! Time to do my research and see whether there is any chance to take part in their IDO. Thanks for the alpha!